SSZTBD9 April 2016
Engineers designing real-time control systems are constantly faced with the challenge of optimizing performance. These systems require minimal latency where the time delay between sampling, processing, and outputting must fit within a tight time window in order to meet the performance specifications. At the heart of the control systems are math intensive algorithms which are used to calculate the control signals. Utilizing a microcontroller (MCU) that can quickly and efficiently execute mathematical operations is critical towards this objective. Ideally, this MCU would be able to execute the real-time control loops concurrently with the central processing unit (CPU) while it is performing other required tasks. Some systems may even have the need to support power line communications (PLC) using the same MCU.
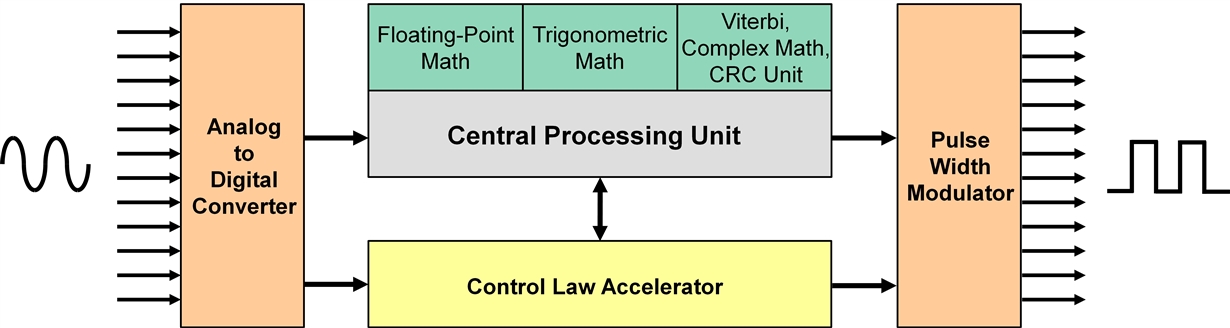
To this end, the TI C2000™ MCUs incorporate a combination of up to four integrated on-chip hardware accelerators that dramatically increase the performance of the device in many real-time applications. The four accelerators include the Floating-Point Unit (FPU), real-time co-processor Control Law Accelerator (CLA), Trigonometric Math Unit (TMU) and the Viterbi, Complex Math, CRC Unit (VCU).
Each C2000 MCU is designed around a fast 32-bit fixed-point C28x CPU core which utilizes the best features of digital signal processors and microcontroller architectures. The addition of the FPU to the C28x fixed-point core (C28x+FPU) enables the device to seamlessly support hardware IEEE-754 single-precision floating-point format operations. Since floating-point math provides a large dynamic range as compared to fixed-point math, it becomes easier to develop code and the programmer no longer needs to be concerned about scaling and saturation. Another benefit is the improved robustness, as the values do not wrap around the number line on an overflow or underflow, like they would with fixed-point math. Using the compiler tools makes it easy to write software, as well as porting existing code. The FPU instructions are an extension of the standard C28x instruction set, therefore most instructions will operate in one or two pipeline cycles, and some can be done in parallel. On average, greater than 2.5 times performance improvement can be achieved with floating-point math as compared to fixed-point math.
The CLA is an independent 32-bit floating-point hardware accelerator which has been designed specifically for math intensive computations. It executes real-time control algorithms in parallel with the C28x CPU, effectively doubling the computational performance of the device. Typically, a device using the CLA can achieve about a 1.3 times performance improvement over the C28x CPU in executing various control applications. Also, by using the CLA to service time-critical functions, the C28x CPU is freed up for other tasks, such as communications and diagnostics. Since the CLA has direct access to the various control peripherals, such as the ADC and PWM modules, it is able to minimize latency and have a fast trigger response. The CLA is capable of reading the ADC result register on the same cycle that the ADC sample conversion is completed, thereby providing a “just-in-time” reading of the ADC which reduces the sample to output delay and enables faster system response for higher frequency control loops. With the performance and efficiency advantages of the CLA, complete complex real-time control applications can be implemented on a single device.
The TMU is an extension of the FPU and further enhances the instruction set of the C28x+FPU by efficiently executing trigonometric and arithmetic operations commonly used in control system applications. Like the FPU, the TMU is an IEEE-754 floating-point accelerator which is tightly coupled with the C28x CPU, but where the FPU provides general-purpose floating-point math support, the TMU focuses on accelerating several specific trigonometric math operations that would otherwise be quite cycle intensive. These trigonometric operations include sine, cosine, arctangent, divide, and square root. The compiler tools have built-in support for automatic generation of the TMU instructions, resulting in significantly fewer cycles and dramatically increasing the performance of trigonometric operations. A key benefit of the TMU is an existing C28x design can realize an immediate advantage without the need to rewrite any code, while portability is maintained since the same code can be used on TI MCUs with and without the TMU support.
The VCU is a tightly coupled fixed-point accelerator that improves the performance of communication-based applications by a factor of roughly seven times. Additionally, when utilizing the VCU for these types of applications, a cost savings can be realized by eliminating the need for a separate processor. Besides communications, the VCU is very useful for general-purpose signal-processing applications, such as filtering and spectral analysis. When using a typical MCU to support various communication technologies, there are four key operations that consume most of the processing power: Viterbi decoding, complex Fast Fourier Transform (FFT), complex filters, and Cyclical Redundancy Check (CRC). Using the hardware capabilities of the VCU, an application will significantly benefit by the increased performance over a software implementation.
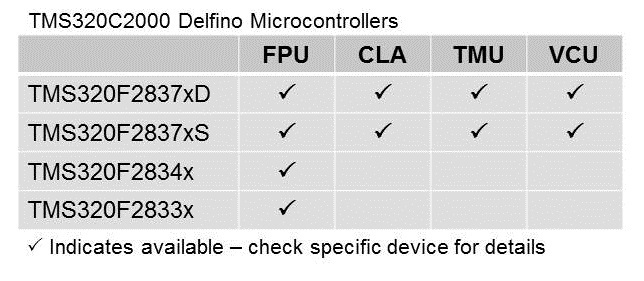
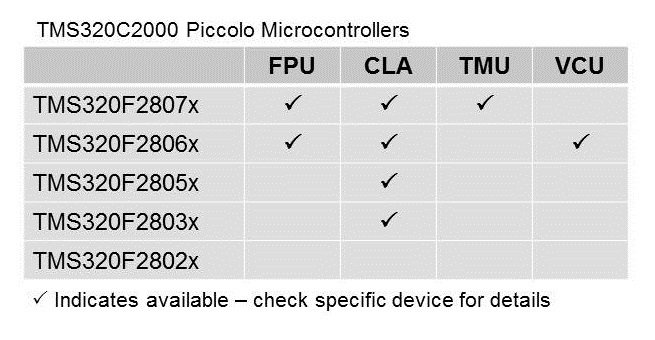
Combining the high performance C28x CPU core with the various advanced hardware accelerators, the fast and efficient processing power required for complex real-time control systems can be realized.
Learn more about the C2000 MCU accelerators:
- Order the C2000 Delfino MCU F28379D LaunchPad Development Kit
- Read more: “Accelerators: Enhancing the Capabilities of the C2000 MCU Family”
- Watch the C2000 Delfino F28377S LaunchPad Development Kit training
- Watch the C2000 F28379D Dual-Core LaunchPad Technical Overview
- Learn more about Delfino MCUs
- Learn more about C2000 MCU Piccolo™ MCUs